
In this post, we’ll go through the steps for developing a dog breed classification application.
Project Definition
Project Overview
In this project, we develop an algorithm that takes in an image and identifies if contains a dog or a human. If it does contain either a dog or a human, the algorithm will classify the dog’s breed or the dog breed that closely resembles that human. This problem falls under the popular category of computer vision.
Problem Statement
Given the project, we would need an algorithm that solves 3 main problems:
- Identify if the image contains human(s)
- Identify if the image contains dog(s)
- Classify the image to a specific breed of dog
To solve these problems we will be using machine learning methods which have shown tremendous progress and produced excellent results in recent years for dealing with such computer vision problems.
We will look at a couple of different methods for each problem and identify which is better. We will also focus on the dog breed classifier and use off-the-shelf tools for the human and dog detectors.
For dog detection, we will assume only one dog that is clearly visible in the image.
For human detection, we will focus on images that have humans with clear faces on them. This simplifies the problem as we would not need to deal with trying to detect human bodies or faces from far away. Thus, our human detector could simply be a face detector. The image could have multiple humans in them but the use case would be specifically for one human (since we would like to identify the resembling dog breed to that human).
Datasets
For the dog breed classifier, we will use the Stanford Dogs Dataset. We use a version that contains about 8351 images with 133 different breeds to classify. We will use this dataset for training, validation, and testing.
When training our model, we need to keep in mind the class distribution for the training set.

We need to ensure that the samples are not too unevenly distributed. We can see here in Figure 1 that the distribution is not exactly even but not too lopsided either.
To test our human detectors, we will use the Labeled Faces in the Wild (LFW) Dataset which contains 13,233 images classified with 5749 different people. For our purposes, we can ignore these classes as we only care about the binary label of human or no human.
Lastly, for our dog detectors, we will mainly use methods trained using the ImageNet Dataset which is a visual object recognition dataset containing more than 14 million images and 20,000 categories. We focus on the categories that label dog breeds. For evaluation, we simply use the Stanford Dogs Dataset.
Metrics
To analyze our data we will use the following metrics:
- Accuracy: We want to know how many correct predictions we get out of all predictions
- Precision: We want to know out of all the positive results how many of them are actually relevant
- Recall: We want to know out of all the relevant results how many of them are actually correctly selected
- F-score: The F-score finds a balance between precision and recall and unifies it into one metric
Each of these metrics will give us a different insight into how our models are performing. Given that our distribution is relatively even, Accuracy would be the more appropriate metric to focus on.
Analysis
Data Exploration and Visualization
First, let’s have a look at some samples from the Stanford Dogs Dataset.


Yes, very nice.
And now, some samples from the Labelled Faces in the Wild (LFW) Dataset.

From Figure 2, we see that the images are mostly closeups of individual faces which is suitable for testing our use case as defined in the problem statement.
Methodology
Data Preprocessing
The datasets that we use are already curated so we would not need to do much cleaning. The Stanford Dog Dataset has already been divided into training, validation, and testing images. The split will be 6680 training images, 835 validation images, and 836 testing images with a ratio of 8:1:1.
Specifically for preprocessing the images to work with ImageNet pre-trained models, we need to do the following:
- Ensure the image is in RGB format
- Resize to 224x224
- Normalize the data from range [0, 255] to [0, 1]
- Normalize the data using the ImageNet means and standard deviations for each RGB channel (mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
For training data, we have one additional step which is data augmentation. This is where we modify the data during training to increase the variation of our input data to help increase the robustness of our model. We augment the data as follows:
- Randomly cropping out parts of the image
- Random horizontal flipping
- Randomly shifting the brightness, contrast, saturation, and hue of the image
Implementation
Human Detector
For our human detector, we look at two methods, one using Haar Cascades [1], and one using a convolutional neural network, MTCNN [2].
For the Haar Cascade method, we use one developed by OpenCV. The model is implemented by OpenCV and they also provide a pre-trained model for face detection.
For MTCNN, we use one provided by this Github repo which also implements the algorithm and provides a pre-trained model.
As both detectors detect faces in the image, we check if the image has at least one detected image of a human.
Dog Detector
For the dog detector, we look mainly at convolutional neural network (CNN) based methods that have been pre-trained on ImageNet. The ones we use are provided by PyTorch. Specifically, we look at VGG16 [4], InceptionV3 [5], and ResNet50 [3]. The models are pre-trained to output 1000 different classes, of which indices 151 to 268 are those representing dog breeds.
Dog Breed Classifier
To classify dog breeds, we will also use a convolutional neural network (CNN) based approach. For this algorithm, we use the Stanford Dog Dataset to train, validate and evaluate the performance. We use PyTorch to implement this.
We first implement a simple CNN model from scratch which we name SimpleNet.

We train our model with the following configurations:
- Loss function: Cross-Entropy Loss
- Optimizer: Adam
- Learning rate: 0.0003 (3e-4)
- Batch size: 20
- Epochs: 20
During training, we periodically validate the model on the validation set and after training, we keep the model with the lowest validation score.
Refinement
After SimpleNet, we also try using a Transfer Learning-based model. In this case, we use ResNet50 and VGG16 pre-trained on ImageNet. We modify the final layer of the network to suit our 133 class output.
When we train the transfer learning models, to prevent overfitting, we freeze the feature extraction (CNN) layers and train only the fully connected classification layers. Otherwise, the training configurations are similar to before.
Results
Model Evaluation and Validation
Human Detector
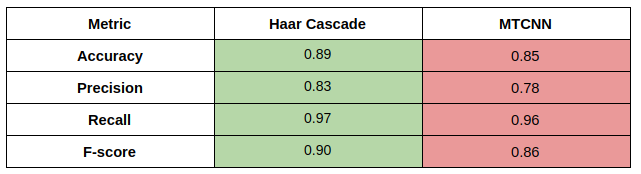
We evaluate both our human detectors on 100 images from the Stanford Dog Dataset and 100 images from the LFW dataset
Dog Detector
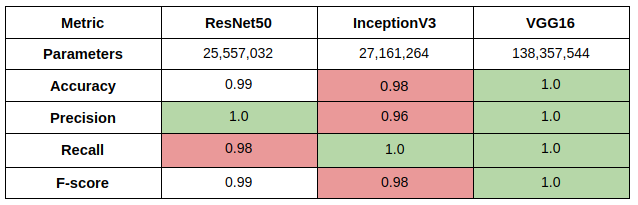
We evaluate our dog detectors similarly, on 100 images from the Stanford Dog Dataset and 100 images from the LFW dataset
Dog Breed Classifier
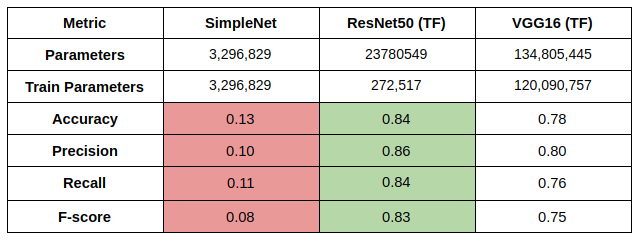
We evaluate our classifiers on the testing set using the saved model with the lowest validation score.
Justification
For the human detector, we find that Haar Cascade performs better than MTCNN. I expected MTCNN to perform better given that it is a more modern deep learning solution but this goes to show that classical methods are still viable. I’m not sure why it performs better, as we are using off-the-shelf tools, this requires some deeper digging that I will leave for later.
For the dog detector, we find that VGG16 performs the best among all the other models. This is expected as VGG16 has the most number of parameters and is the most expressive model.
For the dog breed classifier, we see that ResNet50 performs the best. This is surprising given that VGG16 has a much higher number of parameters. However, we need to consider that the number of training parameters for VGG16 is also very high.
Unlike the case for the dog detector (VGG16 pre-trained on ImageNet was trained by an external source), we trained the model ourselves for only 20 epochs. I expect with more data and more training, the performance for the VGG16 model with transfer learning could perform better.
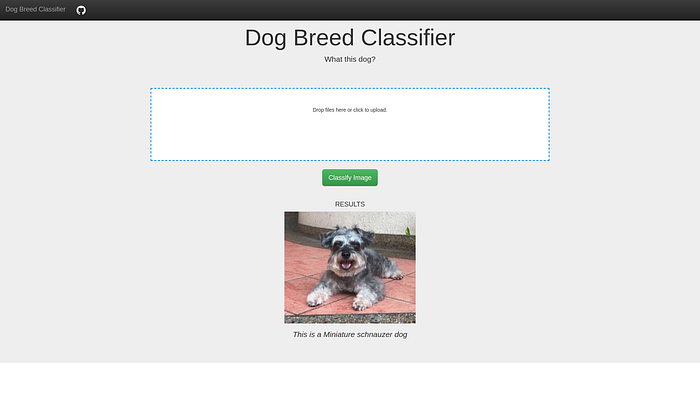
Web Application
Finally, we put everything together into a web application using Flask. You can try out the web application and find out more details in the related Github repo.
Conclusion
Reflection
To sum it up, in this project we looked at and compared two human face detectors. We also looked at and compared three different models for dog detectors.
After this, we built a dog breed classifier based on convolutional neural network architecture. We trained the model from scratch. The training data was augmented by random cropping, horizontal flipping, and color shifting.
Then, we further refined our solution by implementing a transfer learning-based approach which increased our model's accuracy from 12% to 83%.
Finally, we put everything together into an algorithm that identifies if the image contains a human or a dog and classifies the nearest resembling breed. This algorithm is then implemented into a Flask web application.
Overall, working on this project was an enjoyable experience with some interesting results. I learned more about machine learning pipelines and the experimentation process. It’s nice to see how frameworks like OpenCV and PyTorch make it very easy and accessible to carry out these kinds of projects removing any need to re-invent wheels.
It was also interesting to see how different models compare with each other especially for the human face detector where surprisingly the Haar Cascade method performed better than the MTCNN deep learning-based method.
One of the difficulties I faced was dealing with a lack of computation power. During the experiments, there were many a-times where I would have to deal with out-of-memory issues.
In conclusion, it was fun and I’m looking forward to the next one!
Improvements
There are still many improvements that can be made to this project:
- Modify the dog detector using an object detection model such as YOLO, SSD, Faster-RCNN to detect multiple dogs in images and classify each of them
- Crop out each human from an image with multiple humans and classify each of them
- Extend the detection to other kinds of animals
- Experiment with different parameters and hyperparameters
- Experiment with different models
Finally,
If you’d like to dig deeper on this you can check out the related Github Repo for this project
Work done as homework as part of the Udacity Data Scientist Nanodegree
References
- Viola, Paul, and Michael Jones. “Rapid object detection using a boosted cascade of simple features.” Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001. Vol. 1. Ieee, 2001.
- Zhang, Kaipeng, et al. “Joint face detection and alignment using multitask cascaded convolutional networks.” IEEE Signal Processing Letters 23.10 (2016): 1499–1503.
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
- Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
